One of the more confusing things to explain is that a machine is broken “just like last time,” but this time the cause is entirely new. Trust me, this is equally confusing to the troubleshooter who had to figure it out. I think most people would prefer a simple “only A causes B” explanation that is consistent over time. But, just like in life, you can end up in the same place again, even though you took a different path to get there.
One Or More
If you troubleshoot long enough, you’ll eventually experience systems with multiple internal failures. However, even though there may be several things that need to be remedied, this kind of situation often manifests itself in just a single external symptom. A car with a dead battery and an empty fuel tank will not work just like a car with a dead battery or an empty fuel tank. This gets back to our typical experience of failures, where surface-level symptoms and what we are prevented from accomplishing looms the largest in our minds.
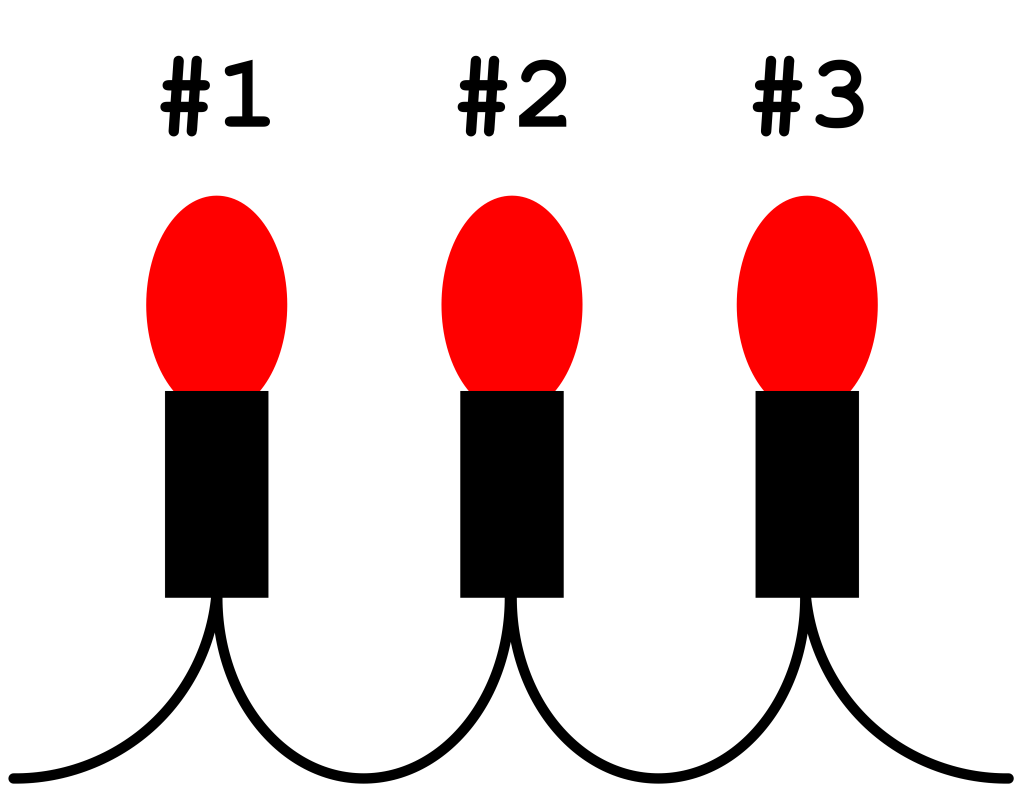
Let’s work through an example and think deeper about situations involving multiple failures. You have a string of 3 red lights, which you have deployed in hopes of creating a festive atmosphere for a party. The string of lights is wired such that all of the lights must individually work for the string to be lit (i.e., if one goes out, the whole string goes out). You’ve had them up in your dorm room, but after your all-weekend rager, they no longer work.
(image: © Jason Maxham)
After you’ve nursed your hangover, you want to show off your troubleshooting skills to your roommate. Consequently, you decide to use a strategy of serially replacing each of the lights with a spare. You’ll swap each lightbulb, one at a time, retesting to see if the string works after each swap. If swapping a specific lightbulb doesn’t work, you’ll put the string back the way you found it and move on to the next light.
As your omniscient narrator, I’ll tell you that the state of the broken system is thus:
- BULB #1: FAILED
- BULB #2: FAILED
- BULB #3: WORKING
As you can see, a serial swap, test, and reset strategy won’t bring this system back to a working state because there are multiple lightbulb failures. Of course, you don’t know that and so you grab a spare bulb and begin the swapping process:
- You swap out BULB #1 with the spare. Test. The lights don’t work (#2 is also failed), so you put the original BULB #1 back in.
- You swap out BULB #2 with the spare. Test. The lights don’t work (#1 is also failed), so you put the original BULB #2 back in.
- You swap out BULB #3 with the spare. Test. The lights don’t work (#1 and #2 are failed), so you put the original BULB #3 back in.
You would be scratching your head at this point, but go where logic leads you: the problem is not likely a single failed bulb. After your swapping exercise, the remaining possibilities are:
- There are multiple failed lightbulbs on the string.
- The spare bulb is faulty. By the way, this is the reason you should always use “known working parts” as replacements: swapping a working part with a broken one increases the number of failures to be discovered and remedied. Unless you like making more work for yourself!
- The problem with the string of lights lies elsewhere, like maybe the outlet you’re plugging into doesn’t have electricity.
One way to get clarity on the state of the bulbs is to reverse the process and take them out of the failed string and place them into another working string. Putting BULB #1 into a working string will cause that string to fail, showing you that BULB #1 is defective. You can test all of the bulbs (including the spare) this way: it’s a play right out of “Copy One That Works.”
Running The Numbers
Given that troubleshooting is about playing the odds, what can we learn about scenarios involving multiple failures? Are they likely and is it worth looking for them? Let’s try to get a sense of the probabilities involved. We’ll stick with our example of that string of stylish red lights, starting by listing all of the possible states of these 3 bulbs:
| Scenario # | Bulb Status | Total Failures | Overall Status | ||
| Bulb #1 | Bulb #2 | Bulb #3 | |||
| 1 | OK | OK | OK | 0 | OK |
| 2 | OK | OK | FAULT | 1 | FAULT |
| 3 | OK | FAULT | OK | 1 | FAULT |
| 4 | FAULT | OK | OK | 1 | FAULT |
| 5 | OK | FAULT | FAULT | 2 | FAULT |
| 6 | FAULT | OK | FAULT | 2 | FAULT |
| 7 | FAULT | FAULT | OK | 2 | FAULT |
| 8 | FAULT | FAULT | FAULT | 3 | FAULT |
You can see there are 8 unique possibilities for how these 3 bulbs can be functioning or broken. We said this particular system requires all 3 bulbs to be working for the system as a whole to operate. Given that, note that only one of these 8 possibilities will result in a working string of lights! Wow. One way to be right and 7 ways to be wrong.
This is a great illustration of a fascinating troubleshooting principle: while there are typically an infinite number of ways for a machine to be screwed up, there’s often only a few ways for it to be right. This is yet another buttress to the “change just one thing at a time” principle and a reminder of why a bias for minimalism should be guiding your repairs. The more mucking around you do, the greater the chances you will be adding to that infinite realm of possible defects.
Next, let’s tally up how many of the above scenarios have 0, 1, 2, or 3 total failures:
| Fault Count | # Scenarios | % of All Scenarios | Overall Status |
| 0 | 1 | 12.5% | OK |
| 1 | 3 | 37.5% | FAULT |
| 2 | 3 | 37.5% | FAULT |
| 3 | 1 | 12.5% | FAULT |
The tally line with a fault count of “0” is the working state, which as stated above is only 1/8th (12.50%) of the total number of possibilities. The next line, with a fault count of “1,” are our singular failures (37.50% of all possibilities). The remaining two entries (marked “2” and “3”) are our multiple failure scenarios: you can see that they represent 50% (37.50% + 12.50%) of the possibilities. If each of these failure scenarios was equally likely, we wouldn’t be having parties very often. Can you imagine buying a machine that only worked 12.5% of the time?!
Don’t get discouraged, most machines will seemingly favor non-operation when going by a raw count like in the table above. However, after weighting the scenarios by their actual likelihood of failure, we find that they are not all equally likely. Continuing with our example, if we assume that each of these bulbs has a 1 in 10,000 chance of failing (per time unit in use), the likelihood of failures involving various combinations of bulbs is much different:
| Scenario # | State % | Combined Probability | Overall Status | ||
| Bulb #1 | Bulb #2 | Bulb #3 | |||
| 1 | 99.99% | 99.99% | 99.99% | 99.9700029999% | OK |
| 2 | 99.99% | 99.99% | 0.01% | 0.0099980001% | FAULT |
| 3 | 99.99% | 0.01% | 99.99% | 0.0099980001% | FAULT |
| 5 | 0.01% | 99.99% | 99.99% | 0.0099980001% | FAULT |
| 4 | 99.99% | 0.01% | 0.01% | 0.0000009999% | FAULT |
| 6 | 0.01% | 99.99% | 0.01% | 0.0000009999% | FAULT |
| 7 | 0.01% | 0.01% | 99.99% | 0.0000009999% | FAULT |
| 8 | 0.01% | 0.01% | 0.01% | 0.0000000001% | FAULT |
Just like before, we can combine the probabilities to get a sense of the relative chance of single versus multiple failures:
| Fault Count | # Scenarios | Combined Probability | Overall Status |
| 0 | 1 | 99.9700029999% | OK |
| 1 | 3 | 0.0299940003% | FAULT |
| 2 | 3 | 0.0000029997% | FAULT |
| 3 | 1 | 0.0000000001% | FAULT |
If a bulb failure was the only thing that could be wrong with our fabulous string of lights, we can see it will be operational most of the time (99.97%). Also, note that the single failure scenario (fault count = 1) is by far the most likely among the various faults listed. By how much? Well, let’s calculate the ratio between the single and multiple failure scenarios to find out. We take the probability of a single failure (0.0299940003%) and divide it by the sum of the “2” and “3” tally lines (0.0000029997% + 0.0000000001% = 0.0000029998%):
0.0299940003% ÷ 0.0000029998% = 9998.66
This result shows the chance of encountering a single failure is nearly 10,000 times more likely than all of the multiple failure scenarios combined! Now that is actionable intelligence. Given the huge drop-off in probability from one to two failures (and then again from two to three failures) you can see it wouldn’t make sense to test all the bulbs if the test was time-consuming or expensive. The odds favor stopping and retesting after identifying that first failed bulb.
Back to our example, the failure of the serial replacement strategy opened the door to the possibility of two or more bad bulbs. However, as soon as you had identified a second failed bulb, it would be wise to stop and retest. Given the truly unlikely scenario of 3 burnt-out bulbs, it doesn’t make sense to pursue it without additional evidence.
A Lack Of Independence
We’ve made one key assumption in the calculation of the statistics above: that a lightbulb burning out is an independent event. That is, if one light bulb burns out it doesn’t affect the probability of another doing the same. When this is true, it leads to the statistics above favoring the single failure. Troubleshooting in the real world, I caution you against making this assumption without evidence. The machines that fill our world are deeply interconnected systems, full of dependencies and linkages, both within themselves and to the larger context in which they are used.

(image: Lance Fuller)
Even for the simple case of a string of lights, it’s easy to think of instances where multiple, coincident lightbulb outages are not independent events: a tripped breaker, an electrical surge blowing the bulbs, a frayed wire in the plug leading to an open circuit, a manufacturing defect in this particular batch of bulbs, etc. I keep stressing the importance of context when troubleshooting, because it allows you to correctly classify a problem and choose the most efficient strategy. Encountering highly improbable multiple failures is a signal that you may have missed an important shared connection: these are opportune moments to step back and consider systemic causes (and solutions).
References:
- Header image: Hush Naidoo, photographer. Retrieved from Unsplash, https://unsplash.com/photos/yo01Z-9HQAw.
