Maybe you’ve had that common recurring dream where you forget to wear pants: to school, to work, or anywhere outside the privacy of your home. If you’re the only one not wearing pants and stalking around in public in just your underwear, it’s pretty embarrassing. However, if everyone isn’t wearing pants—now that’s a party! (Why can’t I have that dream?)
When it comes to wearing pants, context matters: dressing appropriately requires knowing the situation. Reading the environment also benefits troubleshooting and is crucial to choosing the appropriate strategy. You’ll need to understand how the parts relate to the whole, especially when a machine is installed within an interconnected web of supporting systems. As we’ll see, knowing whether machines share symptoms will give you a wealth of additional information that can help pinpoint the source of a problem.
Properly assessing the surroundings ensures that you’re troubleshooting at the correct level: system-wide problems need to be solved system-wide. Lifting your head up and realizing an issue spans multiple systems will ensure that you don’t waste time trying to fix a problem on an individual basis.
Things We Have In Common
Symptoms that are shared across machines can help you to quickly isolate the cause of a problem. Let’s look at an example from the field of networking which will illustrate the power of tuning into shared symptoms. Consider a public library that wants to provide free Internet access to its patrons. Two banks of computers are set up for this purpose:
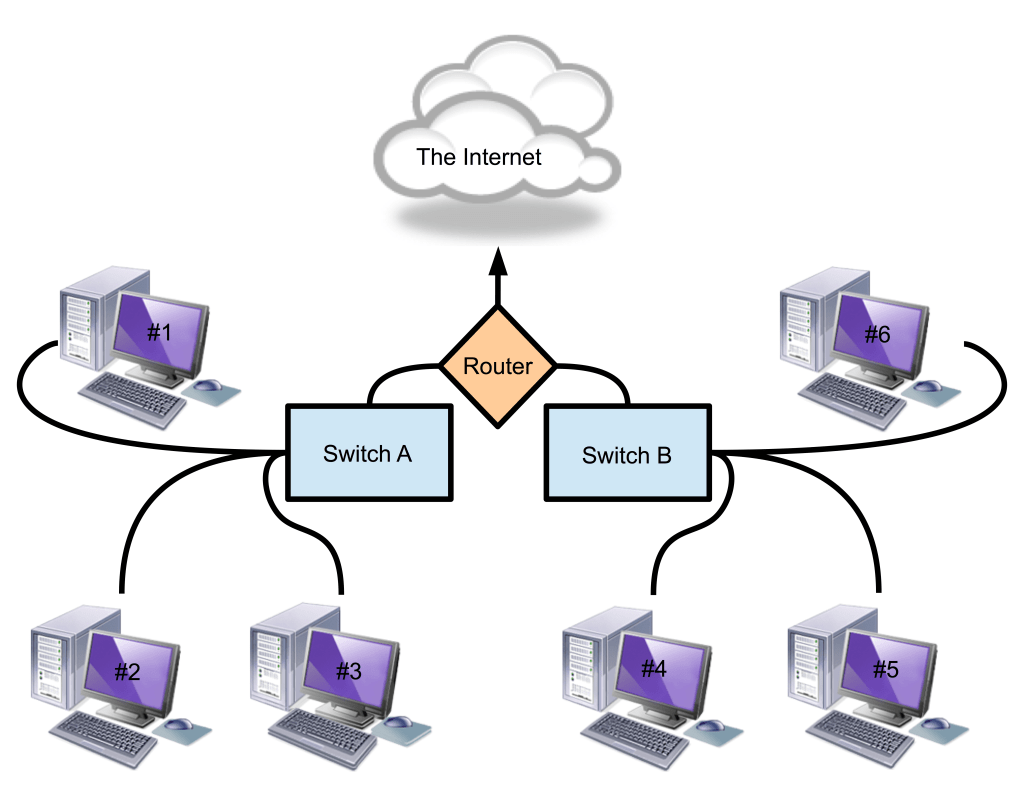
(image: © Jason Maxham)
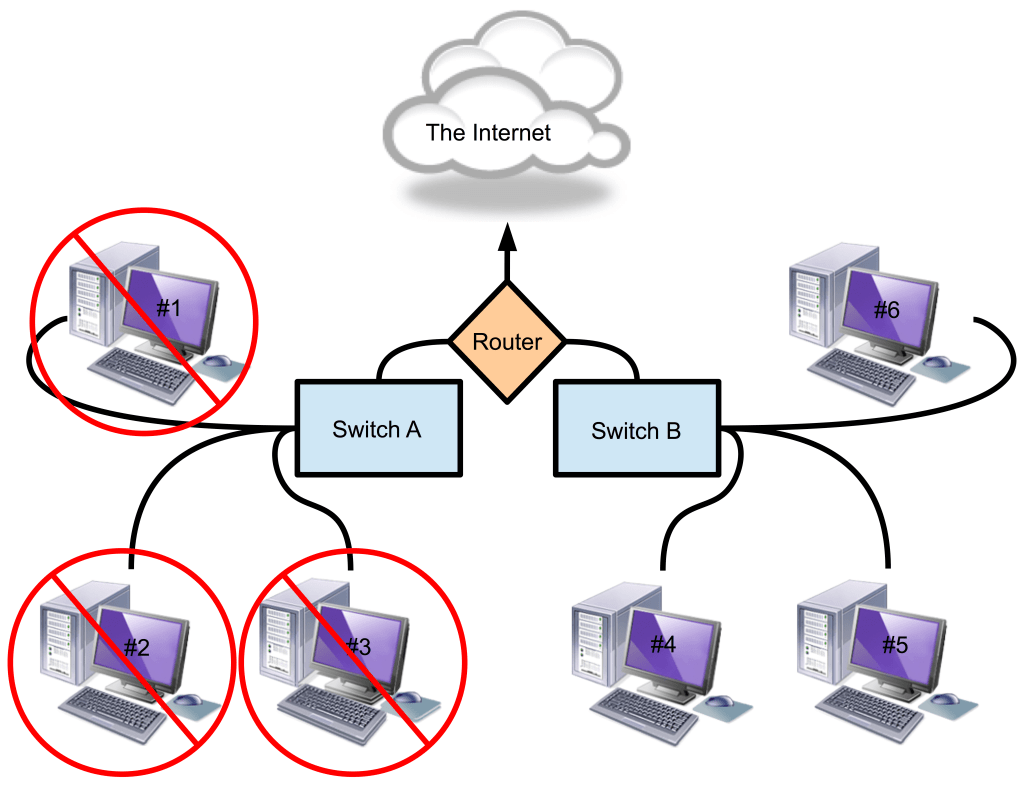
At first, everything works fine, but one day people using computers #1-3 complain that they can’t access the Internet. You verify these claims while also noticing that the patrons sitting at computers #4-6 continue to happily surf away:
(image: © Jason Maxham)
Hmm…what do the computers experiencing the outage (#1-3) have in common? Likewise, how are they different from the computers that can still access the Internet (#4-6)?
Looking at the diagram, the answer to the first question is: Switch A and the cable that connects it to the router. That path to the Internet is shared by all the computers experiencing the problem (#1-3). Examining Switch A, you see that the power cord came loose and the switch is off. You plug it back in and computers #1-3 are able to access the Internet once again!
In our library computer room, different groupings of shared symptoms will point to various components as the source of a problem. For instance, if all of the computers (#1-6) couldn’t access the Internet, then the router and the Internet connection itself would be the best candidates to investigate: these are the only things that are shared by all the computers. Conversely, if only one computer couldn’t access the Internet, there’s a good chance the problem is isolated and internal to that specific machine. By the way, I use the word “candidate” deliberately: noticing shared symptoms is a way to accelerate learning about a failure, but it’s not definitive proof of anything. If all the computers can’t access the Internet, there are a variety of possibilities that are logically consistent with this scenario:
- The Internet connection and/or router is down.
- Switches A+B are both down. As all of the computers are attached to one of these two switches, if they were to malfunction at the same time, it would have the effect of knocking out access to all of the computers.
- Each of the computers (#1-6) is independently misconfigured: perhaps with a virus or errant network settings.
- Any simultaneous combination of the above factors.
Each of the above scenarios could be true, but the power of the “shared symptoms” strategy is that, most of the time, the source of the problem will be the thing held in common. If all 6 computers can’t access the Internet, the law of simplicity says it will be a single cause the majority of the time. To understand why, let’s think about the problem statistically and count the number of things that need to be simultaneously wrong for the various scenarios to be true (again, we’re considering the case where all 6 computers are unable to access the Internet):
| # Failures | Router | Switches A+B | All 6 Computers Properly Configured |
| 0 | OK | OK | OK |
| 1 | FAIL (1) | OK | OK |
| 2 | OK | FAIL (2) | OK |
| 3 | FAIL (1) | FAIL (2) | OK |
| 6 | OK | OK | FAIL (6) |
| 7 | FAIL (1) | OK | FAIL (6) |
| 8 | OK | FAIL (2) | FAIL (6) |
| 9 | FAIL (1) | FAIL (2) | FAIL (6) |
Here, I’ve listed the various possibilities and added up the number of simultaneous failures associated with them. Look at the story described in the bottom row, which tallies 9 simultaneous things wrong: the router (1), both switches (2), and all the computers (6). This is a possible failure condition, but think about how unlikely it would be: the probability of it happening is the product of all 9 scenarios multiplied together! The message rings out loud and clear: in situations with symptoms shared across systems, the odds favor the cause of Just One Thing. Other possibilities require increasingly unlikely coincidences of simultaneous failures.

(image: Mark Baylor / CC BY 2.0)
Wearing A Belt And Suspenders
Failures that involve shared symptoms will expose dependencies that may not have been obvious when you first deployed a system. Sticking with our library example, you might not have realized that plugging computers into a common network switch would mean an outage for all the attached systems when that same switch malfunctions. Now you know! Within that setup, the computers are dependent on the switch for a path to the Internet. Mitigating the negative consequences of dependencies are necessary if you want to create systems that are resilient to failures.
Let’s say that our library is expecting a visit from a very important donor and celebrity. The library’s public relations director has even scheduled a photo op with members of the press that will include our VIP using the Internet. If the Internet were to be inaccessible during the photo op, it would be a huge embarrassment. With so many people milling about, the chance of a power cord being kicked loose is high, so we want to eliminate the chance of a switch failure knocking out access. To make our system more robust, we decide to connect each computer to both switches:
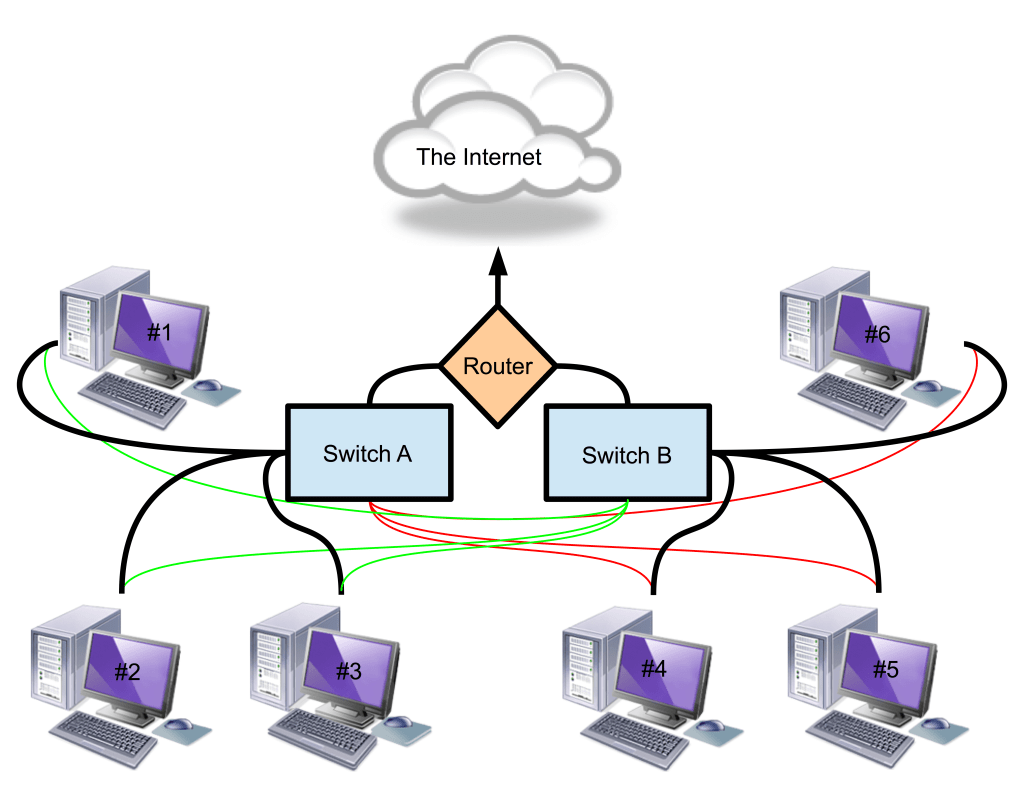
(image: © Jason Maxham)
Now, each computer has two network connections: one to Switch A and one to Switch B. When properly configured to use the extra connection, each computer will have two separate paths to the Internet: one that passes through Switch A and another that passes through Switch B. We have begun the process of eliminating what are known as single points of failure: parts of the system that, when they stop working, cause the system as a whole to fail. You can see that, even after this upgrade, two other single points of failure remain: the router and the Internet connection. How far you go to make your systems highly available is an economic decision. Perhaps the redundant network connections only require an extra set of cables (a small, one-time cost), but another Internet connection will mean an additional router and monthly service charges. How much money we choose to spend on this reliability project all depends on how bad it would be to let down our VIP.
Finally, you might have noticed that the “shared symptom” strategy is closely related to the “shared resources” problem we previously discussed. The distinction is that here we’re not talking about competition for resources between machines, but rather their availability to the system as a whole. When Switch A failed in our example, it wasn’t because one machine was hogging all the network bandwidth. In fact, how the switch failed (from a power loss) was completely independent of how the computers were using the network. The “resource” in jeopardy was a suitable path to the Internet.
Spreading The Sickness And The Cure
There’s another angle from which we can view the “shared symptoms” strategy. Up to this point, I’ve discussed it as information used to pinpoint the location of a failure. However, we can go one step further and actively attempt to create the shared symptoms.
Let’s return again to our library network, to the point in time where we discovered that computers #1-3 were unable to access the Internet. This time, however, let’s say that Switch A is on and appears to be functioning normally, at least based on its indicator lights. What’s a quick way to verify that Switch A is the problem? A clever hack would be to take a computer from the group that’s working (#4-6), plug it into Switch A, and see what happens. Let’s change computer #4’s connection from Switch B to Switch A:
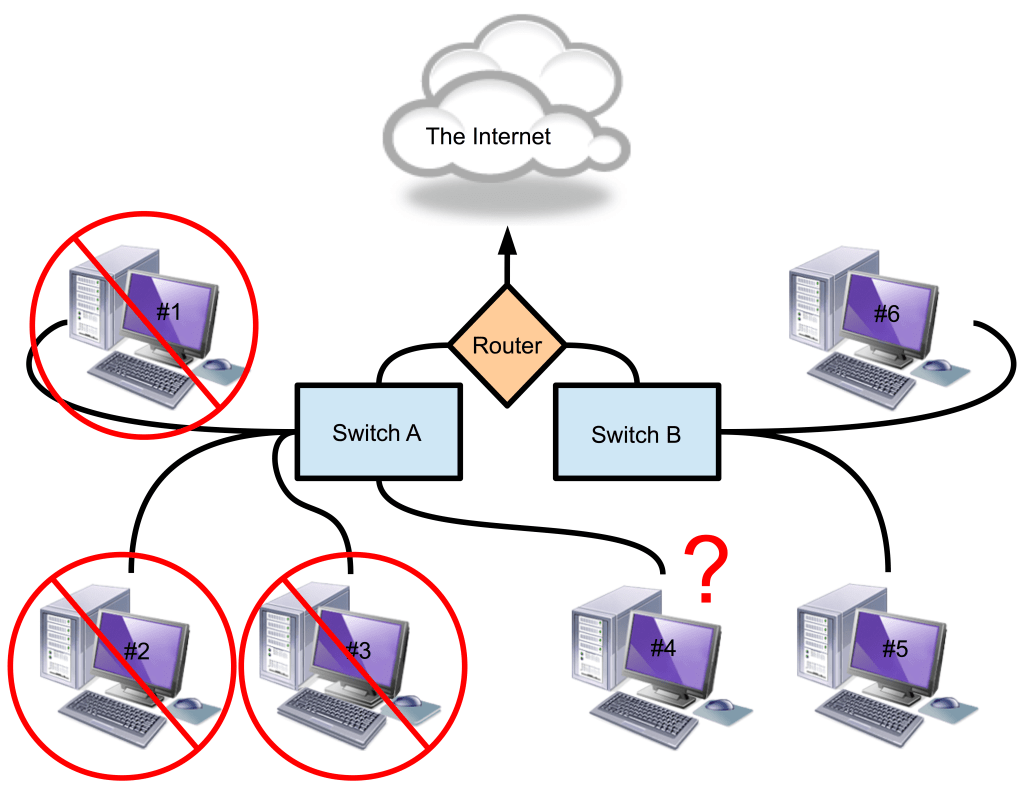
(image: © Jason Maxham)
After we connect computer #4 to Switch A, we find that it can’t access the Internet. Good job! We’ve taken something that worked, made only a single change, and now it doesn’t work. We’ve succeeded in moving the symptom and have learned something valuable in the process. Now, the evidence that Switch A is the culprit is very strong indeed! The converse would have worked as well: we could have taken one of the computers that couldn’t access the Internet (#1-3), connected it to Switch B, and observed the results. We could call this opposite method “spreading the cure” and, for destructive symptoms, that is the preferred way!
One last possibility for this situation is to use a related technique called “moving the problem”: that’s where you take a suspicious component, move its position in the system, and see if the problem follows. In this context, that would mean taking Switch A and putting it in Switch B’s place. If Switch A is the cause of the failure, then it should create problems wherever it goes.
References:
- Header image: “Funicular”. Magda B, photographer. Retrieved from Unsplash, https://unsplash.com/photos/xlRFH9KYyyg.
