When I’m asked to help troubleshoot, I feel a sense of responsibility towards the future. After I’m done, I want it to be fixed. Forever. I suppose this stems from a desire to be competent and the pride I take in my work. Mostly though, it’s that I don’t ever want to be called back to fix something again. There’s something humiliating about triumphantly telling someone “Well, it looks like my job here is done!,” only to have them call you later…and tell you that the problem has reappeared. Going back that second time (or third, or fourth) to fix something again is humbling. Trust me, because I know from firsthand experience.
Even if there’s no one around to witness your humiliation, the reality is that a botched repair can come back to haunt you. Especially if you’re responsible for the smooth operation of a system (i.e., you are the one to be paged in the middle of the night when it fails), I recommend that you truly open your eyes and do everything you can to make sure the problem is fixed for good.
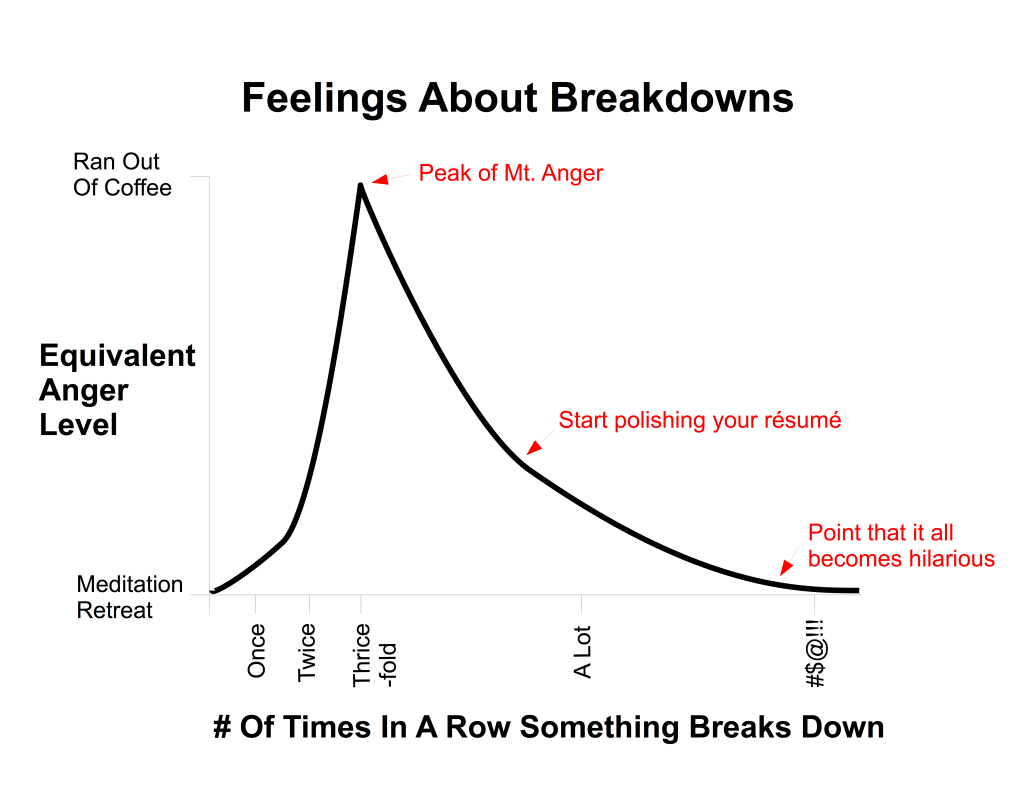
Here’s what I’ve observed about how people react to repeated breakdowns:
(image: © Jason Maxham)
I have personally observed the arc of anger in the graph above: the first time something fails, most people will consider it a fluke. The second time will elicit concern. However, the third time is when people get angry and decide that someone needs to be held accountable: expect a visit from the CEO.
In general, the more a failure happens, the more that people will become desensitized to its effects. It’s exhausting to maintain Peak Anger for very long. Set your expectations for people’s reactions and keep your eyes on the prize: the long-term fix. You’ve got more time than you think between summiting Mt. Anger and the point where you should “start polishing your résumé.”
Of course, it’s preferable to not even start up the trail to Mt. Anger, so the following are strategies to prevent the embarrassing prospect (and related job insecurity) of fixing something only to have it break again.
Pull The Plug, Accelerate The Inevitable
In “Defaults and Reboots,” I discussed the risk of turning a machine off: sometimes a system won’t come back after a cold restart. While I mentioned that as a warning before, in this case we’ll use it to our advantage to learn more about a machine. I call it the “Pull The Plug Test” and it’s as simple as it sounds: after you make your repair, turn the machine off and then turn it back on again. In some cases, I would literally pull the plug on a device and see what happened when I plugged it back in again. You’ll have to use your judgement on how far to take this: in some cases a hard reset like disconnecting a power cord might damage a machine. A gentler, but still effective, method is to shut down a machine using the steps recommended by the manufacturer. Either way, “pulling the plug” can be very illuminating: if a machine fails to work after being reset, it’s better that you discover this on your own terms.
The Pull The Plug Test asks the question: “Will this system continue to operate correctly after some kind of restart?” Power failures aren’t the only thing responsible for restarts, there are many others like scheduled maintenance, refilling supplies (e.g., restocking paper in a copier), human error, etc. An even more likely cause is the natural rhythm of your workplace: things are routinely turned on and off at the beginning of the day, when going to lunch, at the end of a shift, for the weekend, etc.
In those cases where a machine is on the edge of death, turning it on and off again may be the catalyst that finally sends it to the graveyard. These end-of-life failures are often independent of the fix you just performed. That is, it was going to die anyway. Remember, the goal is to learn whether a machine you have finished repairing is fully functional and can be put back in service. If it’s just a single power failure away from the scrap heap, you’ll want to know. The point isn’t to cause destruction, but to get out in front of a future problem. Put another way, would you rather see what is going to happen after a cold restart in a controlled manner, or at 3am on a random Tuesday?
Before executing the Pull The Plug Test, think a move ahead and consider the implications of turning off a machine. Complicated systems may have special restart sequences, so make sure this expertise is available before you get trigger happy with the on/off switch. Very high-risk restarts should be left to a maintenance window.
Spot Configuration Problems
For fixes that involve manipulating a machine’s configuration, the Pull the Plug Test will expose whether your fix will be overridden by a restart. Take the example of a network router that you were called in to look at because data wasn’t getting from point A to B. You easily spotted the problem, made the necessary configuration changes, verified that the data was flowing and then went on with your life. Two weeks later someone bumps the power cable, the device is reset, and the problem comes back! You go through the same troubleshooting cycle, come to the same conclusion as to the cause, and make the same change. What happened? Well, some devices will allow you to make configuration changes that are only valid for a limited period of time: while your login session is active, while the device is powered on, or until some automated process restores a default set of rules. In other words, you made a change to fix the problem, but you didn’t make it permanent.
If the system in question cannot be made to automatically use a particular configuration upon restart, then you’ll need to employ low-tech methods. For example, you can use tape and a marker to show where dials and levers need to be set. Or, have a laminated guide dangling next to the controls that says “TO RESTORE FUNCTIONALITY AFTER A POWER FAILURE, FOLLOW THESE STEPS…”

(image: Jimmy_Joe / CC BY 2.0)
Other Paths To Permanence
A few more ways to prevent false fix-it victories:
- Meet the standard: making sure your repairs conform to a known standard increase their chances of sticking. Are you referring to a repair manual, design schematic or blueprints…or are you just winging it?
- Ask the machine: many machines have built-in diagnostics that’ll tell you when they’re sick and when they’re healthy. Does the machine’s self-reported state confirm the effectiveness of your repair?
- Guilty until proven innocent: be careful with the reuse of parts, especially if you use the shotgun method of replacement. Bad components will lie in wait, ready to sabotage a future repair. When I worked on networks, sometimes we would replace a cable that we suspected was faulty. Later on, that same suspicious cable might end up back in our parts bin with all the other good cables. The funny thing about defective parts is that they can look exactly like working parts! I’ll state the obvious: replacing a faulty part with another faulty part is a sure way to have a problem recur. Burned by the mixing of good and bad cables, I started cutting suspicious ones in half. That absolutely prevented their reuse. Later on, I got a cable tester and we would vet any cable, used or new, before using it as a replacement. Remember, “new” is not the same as “functional.” That’s why you’ll see many manuals use the phrase “known working parts” when taking about replacements.
- Testing and watching: of course you’ll confirm all your fixes by doing some rudimentary testing. It’s even better to watch the person who reported the issue use a machine for real work after a repair. If possible, have them go through their entire workflow, top to bottom.
- Automated detection and alerting: the ultimate solution. Setting up a system to be continuously monitored and then to be notified automatically if there is a regression is the best way to be sure it’s operating normally post-repair. The digital world really shines in this regard, but data collection interfaces can bring this level of certainty to analog processes as well.
Eat Your Dinner, Not Your Words
Perhaps the most important thing you can do is sprinkle in a dash of humility when discussing the results of your troubleshooting. Even if I’m sure I’ve nailed a fix, I prefer to let the results speak for themselves. If you still want that satisfying recognition of victory, be patient: like revenge, it’s best served cold. Wait a few weeks, then ask how things are going with that repair you did. When they say everything is fine (and have paid the bill for the work), then go ahead and take your much-deserved victory lap.
References:
- Header image: Palmer, A. T., photographer. “Bog-downs” and bottlenecks in defense plant operation are out for the duration. Maintenance crews are eternally at it to keep everything in good working order. United States, Ohio, Cuyahoga County, Cleveland. 1941. Dec. [Photograph] Retrieved from the Library of Congress, https://www.loc.gov/item/2017691079/.
