We’ve already been over “duplicating the problem” as a core strategy of the troubleshooting process. However, if you’ve been in the trenches long enough, you know that some problems resist duplication. During these moments, you may shake your fist at the heavens and shout, “Why won’t you fail when I want you to?!” Fixing these tricky issues is when you’ll really earn your pay. Eventually, you’ll appreciate the rewards, both spiritual and material, of solving these tougher failures.
The Black Box
Let’s say that, despite your best efforts, you’re unable to reproduce a problem. Ugh. Well, there is a class of troubleshooting problems, simply known as “intermittent.” They will be difficult to duplicate, even when you have attempted to painstakingly recreate the original environment in which the failure occurred. Of course, you may believe you’ve set up everything the same, but something is different. And that something is making a difference.

(image: © Jason Maxham)
Based on my experience, the inability to recreate a failure is typically a variation of what I call the Black Box Problem. You may have heard the term “black box” thrown around in the world of engineering and product design: it may be used as both a damning slur or a coveted feature, depending on whether you’re hands are covered in grease while cursing or reading a slick marketing brochure.
A Black Box system takes input on one end and magically produces the desired output on the other end. Of course, it’s not really magic, it just seems that way when you don’t know what’s going on inside. For instance, even though I love audio gear, I really have no clue about the inner workings of the amplifier in my stereo. All I know is that I plug my music player in one end and sound comes out the other. Another example is Google, probably the greatest Black Box known to man: you type your search in a box and out springs millions of relevant web pages (although technically theirs is a Blue Box, not a black one). Calling something a Black Box doesn’t mean the system is unknowable: clearly, the original designer of the Black Box knew what was going on internally.
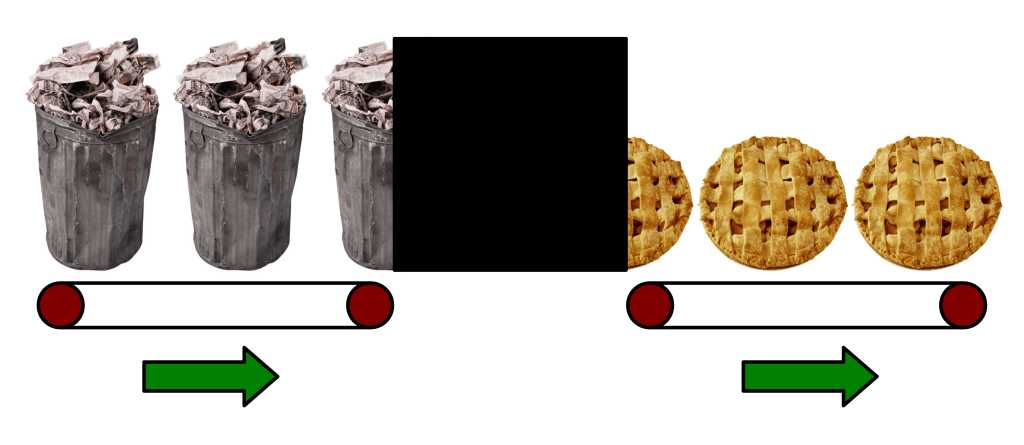
(image: © Jason Maxham)
Hiding complexity behind Black Boxes is essential to enable the average person to use technology in our modern civilization. I don’t care to know the intimate details of what goes on inside my amplifier, I simply don’t have the time or inclination to acquire that knowledge. However, I do want to listen to music in my living room. I might even dance, if the shades are drawn. Likewise, it would be exhausting to have to interact with all of those unshaven programmers at Google every time I wanted to search for something on the Internet. Black Boxes allow a broader range of society to participate in and benefit from technological innovation by making complicated things simple. “Yay!” and a slow clap for all that.
What’s the downside? Well, for the same reason that Black Boxes makes our life easier (you don’t have to know how they work to use them), they also present a problem for the troubleshooter. As long as it works flawlessly, you can be blissfully ignorant of what goes on inside a Black Box. Of course, all machines eventually break down and this is when you’ll need to make the transition from ignorant to enlightened (or preferably beforehand, if you want to be prepared).
If you think that troubleshooters only encounter Black Boxes in the world of off-the-shelf consumer products, think again. The root of the Black Box Problem is a lack of knowledge, so any machine can be a candidate. You may have unwittingly created a Black Box, especially if you’ve cobbled together a Franken-system of parts you didn’t build (Systems Integrators are especially likely to encounter this problem, given this is their job description). Creating a machine with your own two hands won’t confer automatic knowledge of how it will be used, how it will fail, or what happens internally while it is operating. When you build something, you usually devote a lot of time to testing, which is the first-time discovery of these aspects. This learning continues long after a machine is deployed and people begin to report their successes and failures actually using it for work. Designing a machine involves many humbling surprises, so let go of the notion that creating something is the same as knowing it.
In addition to the systems we create, Black Boxes can also spring into existence if knowledge about a system is lost: consider the case where only one person in a company knows how to fix a machine and they retire or leave to take another job. If you’re put in charge of its maintenance and repair, that machine just became a Black Box—to you!
Thinking Inside The Box
The solution to solving intermittent problems is to demystify the Black Box. This means inserting probes to observe the functioning of individual parts, subsystems, components, or stages along a transformational chain. From there, start to look for correlations among those readings to get ideas for further investigation. Looking at data from probes is always mind-expanding: the internal workings of even a machine you think you know well often astonishes. In fact, expect to be surprised: if you knew absolutely everything about the internal workings of a system you’re repairing, you’d already have solved the problem, right? Right.
Circularity: Repeating Positions And Processes
A good start to understanding intermittent problems are what I like to call “circular” components. I put circular in quotes because we’re not always talking about actual circles here, but rather any part that follows a pattern of returning to where it started during the course of doing work. Examples: wheels, fixed-digit counters (e.g., something that goes: “00”, “01”…”99″, “00”), belts, gears, sprockets, chains, gates, switches, pistons, etc.
The relationship to intermittent problems is that one or more of the positions in the repeated pattern may be failing. Many circular systems are designed to keep going even though one of the steps in the cycle is failing. Meshed gears elegantly illustrates this principle:

(image: © Jason Maxham)
First, observe the circular nature of the smaller gear in this machine: it returns to where it started after cycling through all 6 of its teeth.
But, let’s say that one of the teeth on the smaller gear breaks:

(image: © Jason Maxham)
If this machine is designed to do something with each partial turn of the smaller gear, the machine will fail intermittently because of this single broken tooth. Specifically, it will work 5 times in a row, followed by a failure, then work 5 times in a row again, followed by another failure, etc. I’ve numbered the teeth on the smaller gear in the diagram to show you what happens in each iteration:
| Sequence # | Tooth Meshing | Status |
| 1 | 1 | OK |
| 2 | 2 | FAULT |
| 3 | 3 | OK |
| 4 | 4 | OK |
| 5 | 5 | OK |
| 6 | 6 | OK |
| 7 | 1 | OK |
| 8 | 2 | FAULT |
| 9 | 3 | OK |
| 10 | 4 | OK |
| 11 | 5 | OK |
| 12 | 6 | OK |
If you were troubleshooting this machine and being observant, you might notice this predictable ratio of 5:1 successes to failures, along with their reliable sequence. This may be an intermittent problem, but it’s also a very reliable one. Interestingly enough, missing teeth on gears are utilized on purpose in the design of analog counters. For that particular purpose, intermittent behavior is desired: on a counter you want the 10s position to increment only once for every 10 revolutions of the 1s counter. Take a look at the beginning of the video “Building the mechanical counter” (0:30-0:45) to see the use of missing teeth in action for the construction of a counter.
Missing teeth on a gear can be a design feature or cause a breakdown, depending on the context. What lies behind a failure can sometimes be used elsewhere for good. This is a unique perspective on engineering that you will develop as a troubleshooter.
The real world will present you with intermittent failure scenarios far more complicated than the above example of the single missing tooth in a gear. Let’s expand on this and imagine a machine with several intermittently failing “circular” components. Their combined behavior will result in very complicated intermittent failure pattern that will, at first glance, appear to be random.
Let’s start with 3 gears this time and add some broken teeth into the mix:

(image: © Jason Maxham)
Numbering the teeth from the top clockwise, you can see that:
- the blue 6-toothed gear (A) is missing tooth #2
- the green 9-toothed gear (B) is missing tooth #7
- the red 18-toothed gear (C) is missing tooth #4
We’ll set up our scenario with some assumptions:
- The broken gears are located in different places in a machine, independently supporting different functions.
- Gear speed, measured in teeth per minute, is the same for all gears. This means that the gear with 6 teeth will make 3 revolutions in the same time it takes the gear with 18 teeth to make one.
- If any of the gears is currently turning through a broken tooth, the machine will temporarily cease to do its work.
The result of the missing teeth in the separate gears, although acting independently, will together produce a very erratic and intermittent failure scenario:
| Sequence # | Machine Status | Tooth Meshing | ||
| Gear A | Gear B | Gear C | ||
| 1 | OK | 1 | 1 | 1 |
| 2 | FAULT | 2 | 2 | 2 |
| 3 | OK | 3 | 3 | 3 |
| 4 | FAULT | 4 | 4 | 4 |
| 5 | OK | 5 | 5 | 5 |
| 6 | OK | 6 | 6 | 6 |
| 7 | FAULT | 1 | 7 | 7 |
| 8 | FAULT | 2 | 8 | 8 |
| 9 | OK | 3 | 9 | 9 |
| 10 | OK | 4 | 1 | 10 |
| 11 | OK | 5 | 2 | 11 |
| 12 | OK | 6 | 3 | 12 |
| 13 | OK | 1 | 4 | 13 |
| 14 | FAULT | 2 | 5 | 14 |
| 15 | OK | 3 | 6 | 15 |
| 16 | FAULT | 4 | 7 | 16 |
| 17 | OK | 5 | 8 | 17 |
| 18 | OK | 6 | 9 | 18 |
| 19 | OK | 1 | 1 | 1 |
| 20 | FAULT | 2 | 2 | 2 |
| 21 | OK | 3 | 3 | 3 |
| 22 | FAULT | 4 | 4 | 4 |
| 23 | OK | 5 | 5 | 5 |
| 24 | OK | 6 | 6 | 6 |
| 25 | FAULT | 1 | 7 | 7 |
| 26 | FAULT | 2 | 8 | 8 |
| 27 | OK | 3 | 9 | 9 |
| 28 | OK | 4 | 1 | 10 |
| 29 | OK | 5 | 2 | 11 |
| 30 | OK | 6 | 3 | 12 |
| 31 | OK | 1 | 4 | 13 |
| 32 | FAULT | 2 | 5 | 14 |
| 33 | OK | 3 | 6 | 15 |
| 34 | FAULT | 4 | 7 | 16 |
| 35 | OK | 5 | 8 | 17 |
| 36 | OK | 6 | 9 | 18 |
If you could only see the external result, this machine’s behavior would seem very bizarre. Sometimes it fails once and sometimes twice in a row, with the sequence of successes and failures being: 1,1,1,1,2,2,5,1,1,1,2. Also, it takes 18 iterations for the complete failure pattern to emerge! Of course, you wouldn’t even begin to recognize it as a discrete pattern until you had observed two full cycles (that’s why I included 2 × 18 = 36 iterations in the table above). Would you have the patience to observe and systematically record all this until the sequence emerged? I doubt I would.
A Cover-up: The Masking Effect Of Time-Aligned Failures
Now, we’ll examine how concurrent failures can hide each other. Let’s take the gears from the previous example and mount them on a common driveshaft:
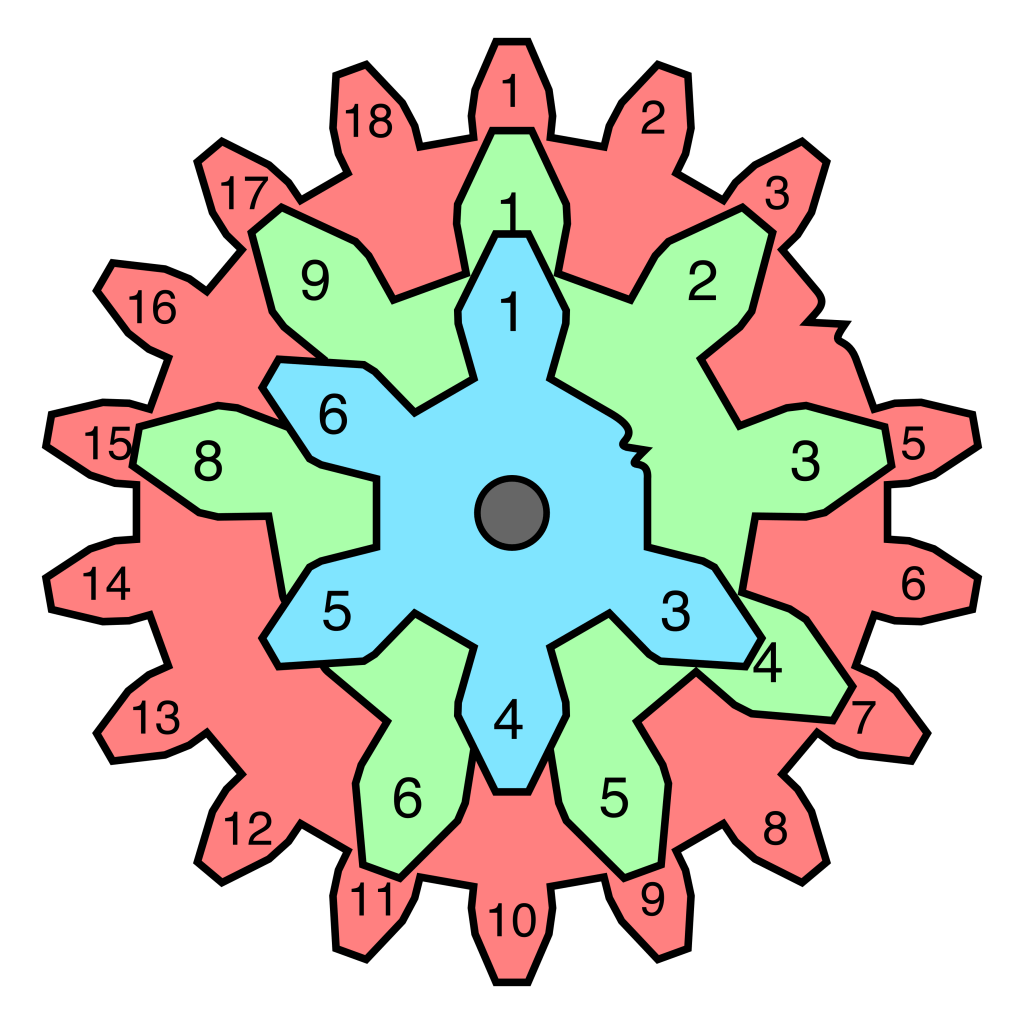
A (6-teeth, blue): #2
B (9-teeth, green): #7
C (18-teeth, red): #4
(image: © Jason Maxham)
For this example, we’ll say that these aligned gears (A,B,C) are meshed at the 12 o’clock position with 3 separate gears (those connecting gears not shown in the diagram). As before, we’ll assume that if any gear is meshing on a broken tooth, the machine will temporarily stop doing its work. Also note: because the gears are being spun by the same driveshaft, the time it takes for the small gear to turn through 6 teeth is equal to the time it takes the larger gear to turn through 18 teeth. Here’s what the failure pattern will look like:
| Sequence # | Machine Status | Tooth Meshing | ||
| Gear A | Gear B | Gear C | ||
| 1/18 | OK | 1 | 1 | 1 |
| 2/18 | OK | 1 | 1 | 2 |
| 3/18 | OK | 1 | 2 | 3 |
| 4/18 | FAULT | 2 | 2 | 4 |
| 5/18 | FAULT | 2 | 3 | 5 |
| 6/18 | FAULT | 2 | 3 | 6 |
| 7/18 | OK | 3 | 4 | 7 |
| 8/18 | OK | 3 | 4 | 8 |
| 9/18 | OK | 3 | 5 | 9 |
| 10/18 | OK | 4 | 5 | 10 |
| 11/18 | OK | 4 | 6 | 11 |
| 12/18 | OK | 4 | 6 | 12 |
| 13/18 | FAULT | 5 | 7 | 13 |
| 14/18 | FAULT | 5 | 7 | 14 |
| 15/18 | OK | 5 | 8 | 15 |
| 16/18 | OK | 6 | 8 | 16 |
| 17/18 | OK | 6 | 9 | 17 |
| 18/18 | OK | 6 | 9 | 18 |
Again, a more complicated pattern emerges with multiple failings gears, versus just a single failing gear. An interesting aspect of this example is that the missing teeth on Gear A (#2) and Gear C (#4) mesh at the same time. You can see from the table that these time-aligned failures mask each other. Even if you found and fixed the missing tooth on Gear C, the machine would still fail the same way until you also fixed Gear A.
It Only Gets Weirder
Hopefully, by now you’ve grasped the concept: malfunctioning parts, each with their own patterns, can act together to produce much more complicated and intermittent failures. When viewed individually, the broken gears I’ve used as examples at least have a reliable error sequence. While gears are a great model for understanding intermittent failures, in the wild be prepared for malfunctioning components with no discernible failure pattern. Combine several of these together and you’ll have a recipe for intermittency that looks perfectly chaotic.
When I see completely random behavior like this, I like to take my investigation “up a level” and look for environmental or system-wide explanations. What comes to mind is the time when the cooling system in our data center went down. As our servers were pushed out of their recommended temperature ranges, very strange things began to happen. Random reboots, crashes, slowness. Everything bad, and in large quantities. Even under normal conditions, the usage patterns of individual servers in a computing cluster are highly variable and dependent upon the work being performed. Add to that a cooling system loss, which brings the uneven effects of hot air collecting and dispersing in a disorderly fashion, and you have a recipe for failures that will be impossible to duplicate.

(image: RobbieMcConnel / CC BY-SA 3.0)
Running On Empty
A related concept to “circular” components are things that might be “filling up” or “running out.” Depending on what is being emptied or filled, these conditions may cause a machine to stop operating intermittently. On the “filling up” side, this could be something like a reservoir that holds waste fluids or the output tray on a copier. When it comes to things “running out,” examples might include fuel being fed to a motor or disk space on a computer. The key is that the fill or depletion rate might vary, making the timing of the failure variable as well. Combine several of these buffers or reservoirs that are “filling up” with other resources that are “running out” and you have the recipe for very complicated intermittent failure scenarios (similar to the multiple gears example above).
Probes and gauges to the rescue! If you can be aware of the “filling up” and “running out” of the machine’s resources, you can begin to correlate these events to breakdowns. Automated monitoring and alerting is the preferred end game for catching things that have run out or filled up (e.g., a “low oil” light on an automobile dashboard).
What’s Going On In There, In The Space Between?
Once you’ve opened up the Black Box, you can see if the internal components are behaving in a predictable way. If you look closely enough, you may find otherwise. Testing the parts individually, you may find that one (or more) is failing intermittently and therefore causing the intermittent failure of the entire machine.
Take the example of an internal combustion engine as seen from the perspective of your average car owner: they put gas in one end and the car gets propulsion on the other. Another Black Box. Of course, there’s a lot going on inside an engine and there’s a long list of things that must be right for it to work properly. When it comes to monitoring, you could watch the pressure inside every cylinder, the spark plug voltage during the firing/recharge cycle, the consistency of the air/gas mixture, etc. If you think obtaining this level of detail is fantasy, you probably have never seen a modern analyzer in an auto repair shop. Engine analysis before the era of computers used more primitive tools and therefore more work was required to gather this kind of data. But, antique or modern, the need to dig into and understand the Black Box is the same. Understanding the whole by understanding the parts is a key part of this demystifying process.
While we’re probing the goings-on within the Black Box, we also need to include the interfaces between components. These points of connection are another common source of intermittent failures. They include examples like: oxidized contacts between a speaker and an amplifier, a broken clip on a network cable, or a loose screw that terminates a wire in an electrical plug. I think there’s two main reasons why these “in-between” parts are so vulnerable to wear and tear:
- They are often conduits responsible for transferring energy or work. You may have heard the expression “Where the rubber meets the road.” This a perfect description of the function of interface parts and the reason why they take such abuse.
- Within their context, these parts are often externally located and therefore more exposed to hazards or the elements. You can have a beautiful machine encased in titanium, but it likely has a power cord coming out of the side, which can be punctured, squished against a wall, or rubbed until it’s bare.
Quantum Troubleshooting
Will always having the same inputs lead to the same outputs when troubleshooting? Chaos theory would say otherwise. Yes, if everything was exactly the same, down to the subatomic level, perhaps you could guarantee that the same inputs would result in the same outputs. However, until we’re arranging particles at whim, you’ll have to realize that there will always be small differences between the original failure scenario and your attempts to recreate it for the purpose of duplication. There’s also one big part of the original context that will be impossible to replicate: time. Even if you could magically place every particle in the exact same place, you simply can’t roll back the clock to recreate the same time context in which a failure occurred (where’s my time machine, already?!).
Troubleshooting is a present and future-oriented exercise. The strategies presented here, especially ones like “don’t fix it,” are pointed toward a future that is much better than the past. Even if you could add a Time Machine to your toolbox, you wouldn’t want to! Alright, a time machine that fits in a toolbox would be pretty cool. It’s just that I’m sure we could find better uses for it than fixing your car. We’d use it to witness important stuff, like the invention of the doughnut.
If your efforts at duplication continue to be thwarted, even after you start monitoring the internals of a system, you might be dealing with a chaotic system. Chaotic systems will take small differences in starting input and turn them into very large differences in outputs. This will manifest itself in behavior that appears to be random. It’s not a machine, but a good example of a system that frequently resists duplication is the weather. Even though some of the parts are well understood (how clouds form, seasonal temperature patterns, effects of changes in atmospheric pressure, etc.), they interact in unexpected ways on a massive scale that frustrates reliable prediction. The weather may be the ultimate example of this, but I’ve worked on systems that are just as frustrating to understand. For the curious, there’s a whole field of research devoted to the “control of chaos.” The technology that makes lasers possible (the awesome-sounding “OGY Method”) was one of the first achievements in the battle against chaos.
Chaotic systems tend to be very complicated (or at least appear so) and have many components, so prepare for some serious troubleshooting. Here are some strategies for bringing stability to a chaotic system:
- Reduce complexity: pare back the number of subsystems, variables, and settings, along with opportunities for interactions between them. Especially in networked systems, where every node is connected to every other node, the number of possible connections grows exponentially as you add nodes.
- Lock down and standardize the flow between parts: you may need to introduce governors or limiters to dampen the effects of swings in inputs and outputs. Specifying and enforcing limits will make subsystems operate in a narrower band, which can reduce chaotic behavior.
- Use automated monitoring and correction to restore service: until you understand what is driving the chaos, a good temporary solution is to monitor your systems and make automated corrections based on that monitoring. As I point out in “Defaults and Reboots”, sometimes this path is good enough to work indefinitely if the cost of understanding the root cause is prohibitive. Can you automatically press the “reset” switch whenever a system begins to behave chaotically? Open or close pathways, speed or slow throughput, take subsystems on or off line: these are all options when automated monitoring enters the picture.
References:
- Header image: Lee, R., photographer. (1939) Stitching cardboard boxes. Grapefruit canning plant, Weslaco, Texas. United States, Weslaco, Texas, Hidalgo County, 1939. Feb. [Photograph] Retrieved from the Library of Congress, https://www.loc.gov/item/2017782081/.
